

At Levels.fyi, we understand the importance of providing users with a robust search function that enables them to quickly find the information they need. This post will walk you through our implementation of a scalable fuzzy search solution using PostgreSQL, which handles over 10 million search queries per month with a p99 query performance under 20ms.
Search Types
| Type | Count |
|---|---|
| Company | 35K+ |
| City | 6.2K+ |
| Area | 300+ |
| Country | 180+ |
| Title | 100+ |
| Specialization | 40+ |

Individually, total record count is more than 42K records across six tables. Besides these, we also support compound search types such as Company x Title (Google Software Engineer) and Title x Company (Software Engineer Google / Software Engineer at Google), resulting in hundreds of thousands of additional records.
Starting Simple
Take the example of someone trying to search for JPMorgan Chase using a query like jp. A starting SQL query might look something like this:
@set q = 'jp%'
SELECT c.name FROM company c WHERE c.name ILIKE $q
UNION SELECT c.name FROM city c WHERE c.name ILIKE $q
...
ORDER BY name
LIMIT 10;While its a decent start, ranking is not taken into consideration here. But we’ll address that later. Above, the query is performing a sequential scan on all the tables. To optimize this, we can simply add a lowercase BTREE index over the searched column and query using LIKE instead of ILIKE. Without normalizing the case, it would be impossible for the database to use the index.
For efficiency during lookups, we create lowercase indexes:
CREATE INDEX company_name_lower_index ON company(LOWER(name));
CREATE INDEX city_name_lower_index ON city(LOWER(name));
...⚠️ Using
CREATE INDEXwill lock writes and updates on the table. If this is an issue, useCREATE INDEX CONCURRENTLY(though it is more expensive). Read More
Optimizing Further
Creating so many indices and aggregating so many tables is sub-optimal. To optimize this, we employ materialized views, which create a separate disk-based entity and hence support indexing. The only downside is that we have to keep it updated.
CREATE MATERIALIZED VIEW search_view AS
ㅤㅤSELECT c.name FROM company c UNION
ㅤㅤSELECT c.name FROM city c UNION ...;
CREATE INDEX search_view_name_lower_index
ㅤㅤON search_view(LOWER(name));
Now, our search query would look something like this:
@set q = 'jp%'
SELECT s.name FROM search_view s
WHERE LOWER(s.name) LIKE LOWER($q)
ORDER BY s.name;To keep the materialized view synchronized, we use an Event Bridge rule that invokes a lambda every X minutes refreshing the materialized view. This means our search results could be stale for a maximum of X minutes, but they would still eventually be consistent.
⚠️ Implementing
INDEX ONLY SCANby including all selected columns in the index can reduce the need for a heap lookup, but this approach does have its limitations. Read More
Core Issues
Our search does have limitations. For instance, a search for jp morgan% wouldn't yield any results because the name we stored is JPMorgan Chase. Even a prefix + suffix query - %jp morgan% wouldn't help here. Expanding the search using arbitrary wildcards %jp%morgan% would help, but it would still fail to deliver results for a search like jp chase%. Phonetics and language present another challenge. If a user searches for the sofy, they could mean sofi, since the is a stop word and i can be misheard as y.
Wildcard searches are helpful, but as the queries become more arbitrary, these searches start to break down. Along with the diversity of our users’ searches, we also need to figure out how to rank our search results. So we decided to take a step forward.
⚠️ Non-prefix searches result in sequential scans. To efficiently search with arbitrary wildcards, you can use trigram indexing. Read More

Full Text Search
Direct searches on the name column are incredibly challenging. To improve search results, we switched to using full text searches with tsvector, a data type that allows for text searching.
@set q = 'the:*&jp:*&chase:*'
SELECT
ㅤㅤs.name,
ㅤㅤto_tsvector('english', s.name),
ㅤㅤto_tsquery('english', $q),
ㅤㅤts_rank(
ㅤㅤㅤㅤto_tsvector('english', s.name),
ㅤㅤㅤㅤto_tsquery('english', $q))
FROM search_view s;| name | to_tsvector | to_tsquery | ts_rank |
|---|---|---|---|
| JP Global Digital | 'digit':3 'global':2 'jp':1 | 'jp':* & 'chase':* | 0 |
| JPS Health Network | 'health':2 'jps':1 'network':3 | 'jp':* & 'chase':* | 0 |
| JPMorgan Chase | 'chase':2 'jpmorgan':1 | 'jp':* & 'chase':* | 0.09910322 |
| JP Services | 'jp':1 'servic':2 | 'jp':* & 'chase':* | 0 |
To eliminate the overhead of converting the name to tsvector, we embedded tsvector as a precomputed entity in the materialized view. We also used a Generalized Inverted Index (Trigram) to optimize the running time of queries. With these changes, our search query would look like this:
@set q = 'the:*&jp:*&chase:*'
SELECT s.name
FROM search_view s
ORDER BY ts_rank(
ㅤㅤs.search_vector,
ㅤㅤto_tsquery('english', $q)) DESC
LIMIT 10;For a query like D E Shaw, the new method reviews the rank and search column:
| name | ts_rank |
|---|---|
| The D. E. Shaw Group | 0.26832977 |
| Eric L. Davis Engineering | 0.18784232 |
⚠️ There are other methods for converting a query to a vector like
websearch_to_tsquery, different types of ranking methods likesimilarity,ts_rank_cdand highlighting helpers likets_headlinethat might be better suited to your use case. Read More
Search Aliases
Several companies have alternative names, either because of a business rebrand or because they have a strong connection between different names:
- Google → Alphabet
- Facebook → Meta
- JPMorgan Chase → JPMC

Our business admins work hard to maintain a comprehensive list of possible alternative company names. To account for alternate names in our search, the search column becomes a combination of the name and its aliases, automatically accounting for them in the search results.
Tweaking Search Ranking
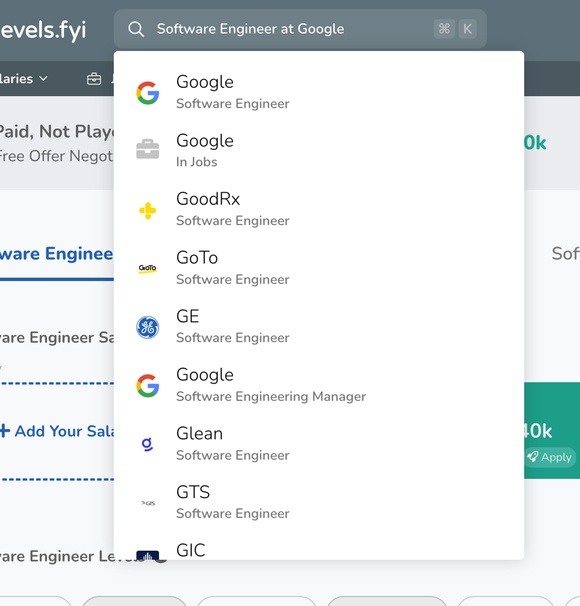
When we search for goo, its likely that we are trying to visit Google but query returned these instead:
| name | ts_rank |
|---|---|
| Goose Bay | 0.06079271 |
| Goose Prairie | 0.06079271 |
| Goodna | 0.06079271 |
| 0.06079271 | |
| Goodwin | 0.06079271 |
While these results have the same rank as per lexeme matching, it doesn't provide the best user experience. To address this, we've developed our own relevancy algorithm on top of similarity and ts_rank. The question is, how do we determine which result is more likely to be clicked? One simple indicator is the number of clicks a result receives. This ensures that the more popular a result becomes, the higher it ranks.
We can't share the exact formula for our search ranking, but here are the few parameters we consider:
- Exact match (rank #1)
- Frequency of matching lexemes using
ts_rank - Similarity score using
similarity - Type of record
- Popularity of the search result
- Similarity between the result’s alias and query
- Inverse of the result’s string length
This approach allows us to fine-tune our search ranking and deliver relevant results to our users.
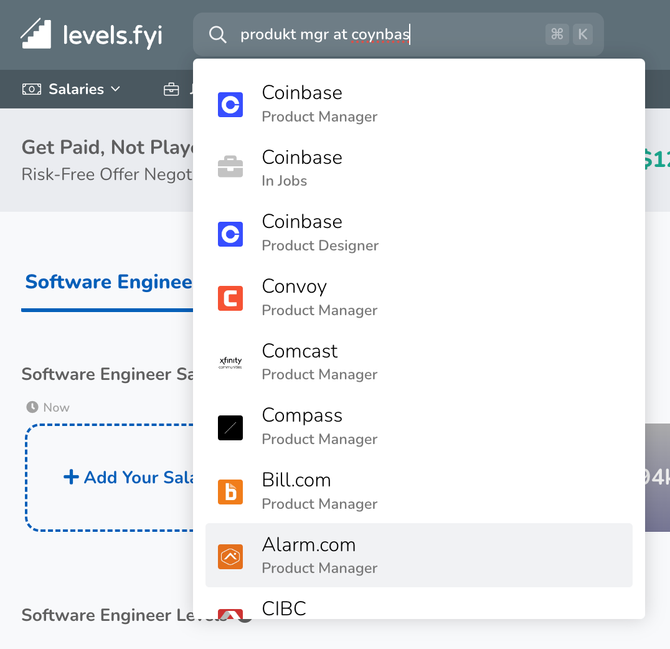
Compound Search Types
We noticed that users were combining search types, for example, "Product Manager at Coinbase" or "Coinbase Product Manager". This posed a challenge because searching by company led users to a salary page, after which users still had to navigate to their title. To eliminate this extra step, we decided to add support for compound types, especially "Company x Title" and "Title x Company" combinations.
Since we're using a materialized view, updating its definition with the results of a cross-join with the company and title tables was straightforward. We also added some extra checks to avoid leading users to nonexistent pages.
Conclusion
We have come a long way from using client-side indexOf matching to implementing a full-blown search solution. While exploring the latest tools can be tempting, it's crucial to approach decisions with a fresh perspective, considering the trade-offs of time, cost, and control. Dedicated search tools like OpenSearch come with their own set of challenges, such as keeping data in sync, maintaining strict security policies, and managing additional infrastructure and tools.

At Levels.fyi, we value PostgreSQL as highly as we value Google Sheets. By investing in PostgreSQL, we have empowered ourselves with advanced query capabilities and cost-effective, scalable solutions for our data needs. Our usage pattern and scale were well-served by PostgreSQL, and by utilizing our in-house solution, we have avoided potential expenses ranging from hundreds to thousands of dollars per month compared to alternative methods. Plus, it's great to finally be on a real database! 😂
Also check out: How Levels.fyi scaled to millions of users with Google Sheets as a backend